Graph mining
Our mission is to build the most scalable library for graph algorithms and analysis and apply it to a multitude of Google products.
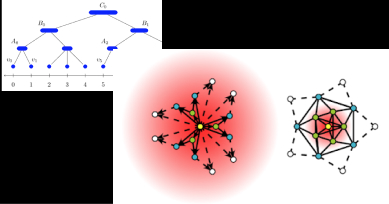
Our mission is to build the most scalable library for graph algorithms and analysis and apply it to a multitude of Google products.
About the team
We formalize data mining and machine learning challenges as graph problems and perform fundamental research in those fields leading to publications in top venues. Our algorithms and systems are used in a wide array of Google products such as Search, YouTube, AdWords, Play, Maps, and Social.
Team focus summaries
Balanced Partitioning splits a large graph into roughly equal parts while minimizing cut size. The problem of “fairly” dividing a graph occurs in a number of contexts, such as assigning work in a distributed processing environment. Our techniques provided a 40% drop in multi-shard queries in Google Maps driving directions, saving a significant amount of CPU usage.
Our team specializes in clustering graphs at Google scale, efficiently implementing many different algorithms including hierarchical clustering, overlapping clustering, local clustering, and spectral clustering.
Connected Components is a fundamental subroutine in many graph algorithms. We have state-of-the-art implementations in a variety of paradigms including MapReduce, a distributed hash table, Pregel, and ASYMP. Our methods are 10-30x faster than the best previously studied algorithms, and easily scale to graphs with trillions of edges.
Our similarity ranking and centrality metrics serve as good features for understanding the characteristics of large graphs. They allow the development of link models useful for both link prediction and anomalous link discovery. Our tool Grale learns a similarity function that models the link relationships present in data.
Our research in pairwise similarity ranking has produced a number of innovative methods, which we have published at top conferences such as WWW, ICML, and VLDB. We maintain a library of similarity algorithms including distributed Personalized PageRank, Egonet similarity, and others.
Our research on novel models of graph computation addresses important issues of privacy in graph mining. Specifically, we present techniques to efficiently solve graph problems, including computing clustering, centrality scores and shortest path distances for each node, based on its personal view of the private data in the graph while preserving the privacy of each user.
We perform innovative research analyzing massive dynamic graphs. We have developed efficient algorithms for computing densest subgraph and triangle counting which operate even when subject to high velocity streaming updates.
ASYMP is a graph mining framework based on asynchronous message passing. We have highly scalable code for Connected Components and shortest-path to a subset of nodes in this framework.
Google’s most famous algorithm, PageRank, is a method for computing importance scores for vertices of a directed graph. In addition to PageRank, we have scalable implementations of several other centrality scores, such as harmonic centrality.
The GraphBuilder library can convert data from a metric space (such as document text) into a similarity graph. GraphBuilder scales to massive datasets by applying fast locality sensitive hashing and neighborhood search.
Featured publications
Highlighted work
-
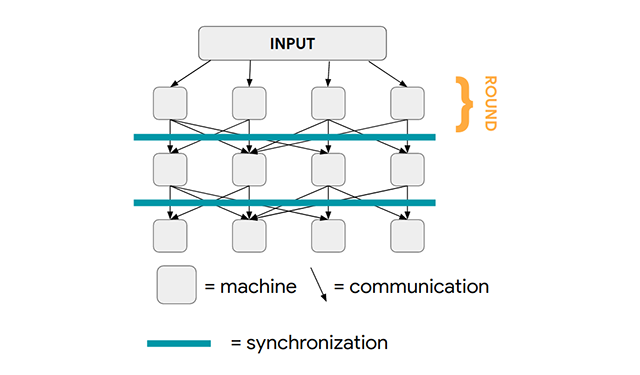 Massively Parallel Graph Computation: From Theory to PracticeAdaptive Massively Parallel Computation (AMPC) augments the theoretical capabilities of MapReduce, providing a pathway to solve many graph problems in fewer computation rounds; the suite of algorithms, which includes algorithms for maximal independent set, maximum matching, connected components and minimum spanning tree, work up to 7x faster than current state-of-the-art approaches.
Massively Parallel Graph Computation: From Theory to PracticeAdaptive Massively Parallel Computation (AMPC) augments the theoretical capabilities of MapReduce, providing a pathway to solve many graph problems in fewer computation rounds; the suite of algorithms, which includes algorithms for maximal independent set, maximum matching, connected components and minimum spanning tree, work up to 7x faster than current state-of-the-art approaches. -
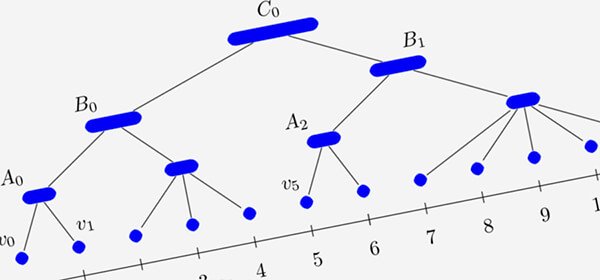 Balanced Partitioning and Hierarchical Clustering at ScaleThis post presents the distributed algorithm we developed which is more applicable to large instances.
Balanced Partitioning and Hierarchical Clustering at ScaleThis post presents the distributed algorithm we developed which is more applicable to large instances. -
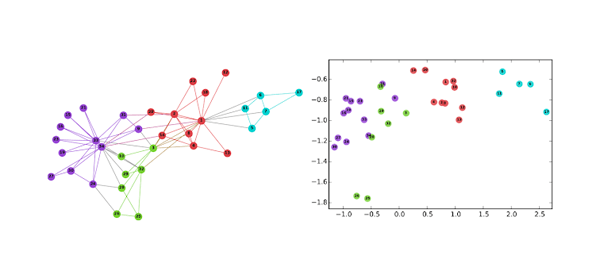 Innovations in Graph Representation LearningWe share the results of two papers highlighting innovations in the area of graph representation learning: the first paper introduces a novel technique to learn multiple embeddings per node and the second addresses the fundamental problem of hyperparameter tuning in graph embeddings.
Innovations in Graph Representation LearningWe share the results of two papers highlighting innovations in the area of graph representation learning: the first paper introduces a novel technique to learn multiple embeddings per node and the second addresses the fundamental problem of hyperparameter tuning in graph embeddings. -
 Graph Mining & Learning @ NeurIPS 2020The Mining and Learning with Graphs at Scale workshop focused on methods for operating on massive information networks: graph-based learning and graph algorithms for a wide range of areas such as detecting fraud and abuse, query clustering and duplication detection, image and multi-modal data analysis, privacy-respecting data mining and recommendation, and experimental design under interference.
Graph Mining & Learning @ NeurIPS 2020The Mining and Learning with Graphs at Scale workshop focused on methods for operating on massive information networks: graph-based learning and graph algorithms for a wide range of areas such as detecting fraud and abuse, query clustering and duplication detection, image and multi-modal data analysis, privacy-respecting data mining and recommendation, and experimental design under interference.
Some of our locations




Some of our people
-

Sara Ahmadian
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +3 more
-

Dustin Zelle
- Data Mining and Modeling
- Machine Intelligence
-

Alessandro Epasto
- Algorithms and Theory
- Data Mining and Modeling
- Machine Intelligence
- +2 more
-

Allan Heydon
- Machine Intelligence
- Software Engineering
- Software Systems
-

Arjun Gopalan
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- Machine Intelligence
-

Jonathan Halcrow
- Algorithms and Theory
- Machine Intelligence
-

Silvio Lattanzi
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +1 more
-

Matthew Fahrbach
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +1 more
-

Vahab S. Mirrokni
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +4 more
-

Bryan Perozzi
- Data Mining and Modeling
- Machine Intelligence
-

Jean Pouget-Abadie
- Algorithms and Theory
- Data Mining and Modeling
- Economics and Electronic Commerce
-

Mohammad Mahdian
- Algorithms and Theory
- Data Mining and Modeling
- Economics and Electronic Commerce
-

Jakub Łącki
- Algorithms and Theory
- Distributed Systems and Parallel Computing
-

Mohammadhossein Bateni
- Algorithms and Theory
- Data Mining and Modeling
- Distributed Systems and Parallel Computing
- +1 more
-

Sasan Tavakkol
- Algorithms and Theory
- Distributed Systems and Parallel Computing
- Machine Intelligence
- +1 more
